Problem to Solve
This project uses natural language processing (NLP) and machine learning techniques to detect stress levels in written texts. The system takes unstructured text as input, preprocesses it, and applies classification models to determine the probability that the text reflects stress. Interactive visualizations help explore data patterns and model results.
1. Dataset Information
The dataset contains texts extracted from different Reddit subreddits, with information about the stress level detected in each text.
Dataset Columns
- subreddit: Specific Reddit community or forum
- post_id: Unique post identifier
- sentence_range: Sentence index within the post
- text: Text used to detect stress
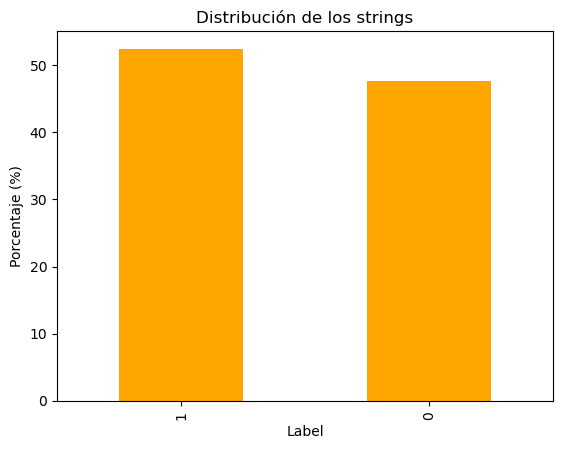
- label: 0 means "no stress", 1 means "stress"
- confidence: Person's confidence level in the text
- social_timestamp: Timestamp recording when the post was published
Dataset Example
| subreddit | post_id | sentence_range | text | label | confidence | social_timestamp |
|---|---|---|---|---|---|---|
| ptsd | 8601tu | (15, 20) | He said he had not felt that way before, sugge... | 1 | 0.8 | 1521614353 |
| assistance | 8lbrx9 | (0, 5) | Hey there r/assistance, Not sure if this is th... | 0 | 1.0 | 1527009817 |
| ptsd | 9ch1zh | (15, 20) | My mom then hit me with the newspaper and it s... | 1 | 0.8 | 1535935605 |
| relationships | 7rorpp | [5, 10] | until i met my new boyfriend, he is amazing, h... | 1 | 0.6 | 1516429555 |
| survivorsofabuse | 9p2gbc | [0, 5] | October is Domestic Violence Awareness Month a... | 1 | 0.8 | 1539809005 |
2. Text Analysis
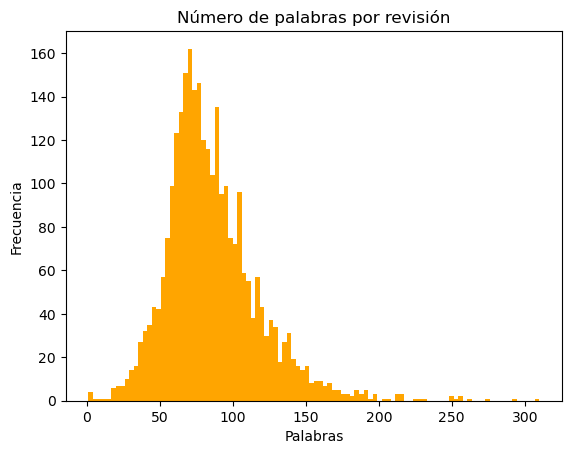
An exploratory analysis of the texts was performed to understand their characteristics and distributions. The average words per text is 85 words.
Words per Review
String Distribution
General WordCloud

3. Processing with NLTK
NLTK (Natural Language Toolkit) is a Python library that provides tools for working with natural language data. It was used to preprocess and normalize texts before model training.
3.1 Normalization and Tokenization
All words were converted to lowercase and texts were tokenized (divided into individual words). By removing duplicates, the number of unique tokens was reduced by 10% with normalization.
from nltk import word_tokenize
token_lists = [word_tokenize(each) for each in df['text']]
tokens = [item for sublist in token_lists for item in sublist]
print("Tokens únicos antes: ", len(set(tokens)))
token_lists_lower = [word_tokenize(each) for each in df['text_new']]
tokens_lower = [item for sublist in token_lists_lower for item in sublist]
print("Tokens únicos nuevos: ", len(set(tokens_lower)))3.2 Special Character Removal
Special characters that do not provide information for classification were removed, such as emojis, symbols, and excessive punctuation marks.
Removed characters: {'"', '🐰', ''', '💕', '>', '\u200d', '+', '_', '\\', '➡', '\t', '\u200e', '🙂', ''', '·', '…', '#', '●', '🎓', '€', '(', "'", '<', '"' , '^' , '´' , '🥕' , '😔' , '😦' , ':' , '"' , '/' , '?' , '❤' , '–' , '%' , '👩' , '@' , '️' , '😇' , '[' , '—' , '-' , '!' , '💸' , '$' , '¯' , '.' , ')' , '&' , ',' , '£' , '=' , '•' , ';' , '~' , ']' , '*' }
3.3 Lemmatization
Lemmatization is the process of reducing a word to its base form or lemma. For example, "running", "runs", and "ran" become "run". This helps normalize variations of the same word.
Before:
"I am feeling anxious and worried. My heart is racing and I cannot stop thinking about problems."
After:
"I be feel anxious and worry. My heart be race and I cannot stop think about problem."
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
lemmatizer = WordNetLemmatizer()
def lemmatize_text(text):
words = word_tokenize(text)
lemmatized_words = [lemmatizer.lemmatize(word, wordnet.VERB) for word in words]
return ' '.join(lemmatized_words)
X_lema = X.apply(lemmatize_text)3.4 Removal of Stopwords and High/Low Frequency Words
Words that do not provide information for classification were removed:
High Frequency Words (removed)
These words appear very frequently but do not provide information:
- ('i', 13907) - appears 13,907 times
- ('to', 8315) - appears 8,315 times
- ('and', 7954) - appears 7,954 times
- ('the', 6236) - appears 6,236 times
- ('a', 5339) - appears 5,339 times
- ('my', 4471) - appears 4,471 times
- ('of', 3634) - appears 3,634 times
- ('it', 3521) - appears 3,521 times
- ('that', 3038) - appears 3,038 times
- ('me', 3036) - appears 3,036 times
Low Frequency Words (removed)
These words appear only once and also do not provide information:
- ('labyrinth', 1)
- ('bureaucracy', 1)
- ('squeeze', 1)
- ('wayne', 1)
- ('guzzler', 1)
- ('lightheadedness', 1)
- ('extremities', 1)
- ('radiates', 1)
- ('disassociation', 1)
- ('usd', 1)
import nltk
nltk.download('stopwords')
eng_stop_words = nltk.corpus.stopwords.words('english')
noise_words = list(eng_stop_words)
processed_stopwords = [word.lower() for stopword in noise_words
for word in word_tokenize(stopword)]3.5 Train-Test Split
The dataset was split before vectorizing to more easily compare original texts with preprocessed ones. This allows maintaining a clear reference of the original data.
3.6 Vectorization (Bag of Words)
Vectorization is the process of converting text into numbers that the machine learning model can process. Bag of Words (BOW) represents each text as a vector where each position corresponds to a word in the vocabulary, and the value indicates how many times that word appears in the text.
bow_counts = CountVectorizer(
tokenizer=word_tokenize,
stop_words=processed_stopwords,
ngram_range=(1, 2) # bigramas
)
X_train_bow = bow_counts.fit_transform(X_train)
X_test_bow = bow_counts.transform(X_test)Why bigrams? Bigrams capture pairs of consecutive words (like "I am", "am stressed"), which helps capture context and relationships between words that are important for detecting stress.
4. Wordclouds Before Training
Wordclouds show the most frequent words in each category, revealing distinctive linguistic patterns between stressed and non-stressed texts.
Comparison: Stressed vs Non-Stressed People

The visual comparison shows differences in word patterns. In texts from stressed people, words like "anxiety", "friend", "work", "need", "back", "time", and "know" appear more frequently and in different contexts than in texts from non-stressed people.
5. Model Training
A Logistic Regression model was trained using stratified cross-validation (StratifiedKFold) to robustly evaluate performance.
Model Results
6. Model Testing
The model was tested with real examples to verify its functionality:
"I am really stressed and anxious"
The model correctly identifies that this phrase indicates the presence of stress.
"I am relaxed"
The model correctly identifies that this phrase indicates the absence of stress.