Problem to Solve
This project implements a binary image classification system that distinguishes between cats and dogs using deep learning techniques. The challenge was to create a convolutional neural network (CNN) using TensorFlow 2.0 and Keras that correctly classifies images of cats and dogs with at least 63% accuracy.
Image classification is a fundamental problem in computer vision. Unlike traditional machine learning approaches that require manual feature extraction, CNNs can automatically learn hierarchical features from raw pixel data, making them ideal for visual recognition tasks.
Model used: Convolutional Neural Network (CNN) with data augmentation
1. Dataset Information
The dataset consists of images organized into three directories: training, validation, and test sets.
Training Set
Size: 2,001 images
- 1,000 images of cats
- 1,000 images of dogs
- Used to train the model
Validation Set
Size: 1,001 images
- 500 images of cats
- 500 images of dogs
- Used to monitor training progress and prevent overfitting
Test Set
Size: 50 images
- Unlabeled images
- Used for final evaluation
- Predictions must maintain order (shuffle=False)
Image Preprocessing Requirements
All images are resized to 150×150 pixels and normalized to values between 0 and 1 (originally 0-255). This standardization is crucial for neural network training as it ensures:
- Consistent input dimensions across all images
- Numerical stability during training
- Faster convergence of the optimization algorithm
2. Image Data Generation
2.1 What is ImageDataGenerator?
ImageDataGenerator is a Keras utility class that provides real-time data augmentation and preprocessing for image datasets. It serves multiple critical functions:
1. Image Loading and Decoding
Automatically reads images from directories and decodes them into tensors (multi-dimensional arrays) that neural networks can process.
2. Data Normalization
Converts pixel values from the range [0, 255] to [0, 1] using the rescale parameter. This
normalization is essential because:
- Neural networks train more efficiently with normalized inputs
- Prevents gradient explosion/vanishing issues
- Allows the optimizer to converge faster
3. Batch Generation
Organizes images into batches for efficient training. Instead of loading all images into memory at once, it generates batches on-the-fly, making it memory-efficient for large datasets.
4. Data Augmentation
Applies random transformations to images during training, effectively creating new training examples from existing ones. This helps prevent overfitting and improves model generalization.
Basic ImageDataGenerator Setup
train_image_generator = ImageDataGenerator(
rescale = 1./255 # Normalize pixel values to [0, 1]
)The rescale parameter divides each pixel value by 255, converting
integers in the range [0, 255] to floats in [0, 1].
2.2 flow_from_directory Method
The flow_from_directory method creates a generator that reads images from a directory structure
and applies the specified transformations.
Creating Data Generators
train_data_gen = train_image_generator.flow_from_directory(
batch_size=batch_size,
directory=train_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='binary'
)
val_data_gen = validation_image_generator.flow_from_directory(
batch_size=batch_size,
directory=validation_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='binary'
)
test_data_gen = test_image_generator.flow_from_directory(
batch_size=batch_size,
directory=test_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='binary',
shuffle=False # Critical: maintains prediction order
)Key Parameters Explained
- batch_size: Number of images processed together (128 in this project)
- directory: Path to the image directory
- target_size: Resizes all images to (150, 150) pixels
- class_mode: 'binary' for two-class classification (cats=0, dogs=1)
- shuffle: For test data, set to False to maintain prediction order
3. Data Augmentation
With a relatively small training dataset (2,001 images), there's a high risk of overfitting—where the model memorizes training examples rather than learning generalizable features. Data augmentation addresses this by creating variations of existing images.
3.1 Why Data Augmentation?
Data augmentation artificially increases the size and diversity of the training dataset by applying random transformations. This helps the model:
- Learn features that are invariant to orientation, position, and scale
- Generalize better to new, unseen images
- Reduce overfitting by exposing the model to more variations
- Improve robustness to real-world image variations
3.2 Augmentation Transformations
Enhanced ImageDataGenerator with Augmentation
train_image_generator = ImageDataGenerator(
rescale = 1./255, # Normalize pixel values to [0, 1]
rotation_range = 40, # Rotate images randomly up to 40°
width_shift_range = 0.2, # Shift horizontally by up to 20%
height_shift_range = 0.2, # Shift vertically by up to 20%
shear_range = 0.2, # Apply shear transformation up to 20%
zoom_range = 0.2, # Random zoom within 20% range
horizontal_flip = True, # Randomly flip images horizontally
fill_mode = 'nearest' # Fill empty pixels using nearest neighbor
)rotation_range = 40
Randomly rotates images by up to ±40 degrees. This teaches the model that object orientation doesn't change the class (a cat is still a cat whether upright or slightly tilted).
width_shift_range = 0.2
Randomly shifts images horizontally by up to 20% of the image width. Helps the model learn that object position within the frame doesn't affect classification.
height_shift_range = 0.2
Randomly shifts images vertically by up to 20% of the image height. Similar to width shift, teaches position invariance.
shear_range = 0.2
Applies a shear transformation (like tilting a rectangle into a parallelogram). Simulates perspective changes and helps with robustness to viewing angles.
zoom_range = 0.2
Randomly zooms in or out by up to 20%. Teaches the model to recognize objects at different scales, which is crucial for real-world applications.
horizontal_flip = True
Randomly flips images horizontally (mirror effect). This is particularly effective for animals since they're generally symmetric horizontally, effectively doubling the dataset.
fill_mode = 'nearest'
When transformations create empty spaces (e.g., after rotation), this fills them using the nearest pixel values. Other options include 'constant', 'reflect', and 'wrap'.
3.3 Visual Example: Data Augmentation in Action
The following image shows how a single cat image is transformed into 5 different variations using the augmentation parameters:

A single training image (left) transformed into 5 variations through random rotations, shifts, zooms, and flips. Each variation is treated as a new training example, effectively increasing the dataset size.
4. CNN Architecture
The model uses a Convolutional Neural Network (CNN) architecture designed to automatically learn hierarchical features from images, progressing from simple edges to complex shapes and patterns.
4.1 Model Architecture
model = keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(128, (3, 3), activation='relu'),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation='sigmoid')
])4.2 Architecture Summary
| Layer | Output Shape | Parameters | Purpose |
|---|---|---|---|
| Conv2D (32 filters) | (148, 148, 32) | 896 | Detects basic features (edges, lines) |
| MaxPooling2D | (74, 74, 32) | 0 | Reduces spatial dimensions |
| Conv2D (64 filters) | (72, 72, 64) | 18,496 | Detects more complex patterns |
| MaxPooling2D | (36, 36, 64) | 0 | Further reduces dimensions |
| Conv2D (128 filters) | (34, 34, 128) | 73,856 | Detects high-level features |
| MaxPooling2D | (17, 17, 128) | 0 | Final spatial reduction |
| Flatten | (36,992) | 0 | Converts to 1D vector |
| Dense (512) | (512) | 18,940,416 | Fully connected classification |
| Dropout (0.5) | (512) | 0 | Prevents overfitting |
| Dense (1) | (1) | 513 | Binary classification output |
Total Parameters: 19,034,177 trainable parameters
4.3 Layer-by-Layer Deep Dive
1. Conv2D(32, (3, 3)) - First Convolutional Layer
Convolution Operation: (I * K)[i,j] = ΣmΣn I[i+m, j+n] × K[m, n]
This layer applies 32 different 3×3 filters (kernels) to the input image. Each filter learns to detect a specific feature:
- Mathematical Process: The filter slides across the image, computing dot products between filter weights and local image patches
- What it learns: Simple features like edges, corners, and basic textures
- Why 32 filters: Allows detection of multiple feature types simultaneously
- Why (3, 3): Small kernel size captures fine-grained local patterns
- ReLU activation: f(x) = max(0, x) introduces non-linearity, enabling the network to learn complex patterns
Output: 148×148×32 (reduced from 150×150 due to valid padding)
2. MaxPooling2D((2, 2)) - First Pooling Layer
Max Pooling: P[i,j] = max(I[2i:2i+2, 2j:2j+2])
Reduces spatial dimensions by taking the maximum value in each 2×2 region:
- Purpose: Reduces computational complexity and parameters
- Benefit: Makes the model more translation-invariant
- Why Max instead of Average: Preserves the strongest features, which are most informative
- Mathematical effect: Halves both width and height: 148×148 → 74×74
Output: 74×74×32 (spatial dimensions halved, depth unchanged)
3. Conv2D(64, (3, 3)) - Second Convolutional Layer
Builds upon the first layer's features to detect more complex patterns:
- Why 64 filters: As we go deeper, we need more filters to capture increasing feature complexity
- What it learns: Combinations of edges forming shapes, textures, and patterns
- Receptive field: Each neuron "sees" a larger area of the original image due to previous pooling
Output: 72×72×64
4. MaxPooling2D((2, 2)) - Second Pooling Layer
Further reduces spatial dimensions while preserving the most important features.
Output: 36×36×64
5. Conv2D(128, (3, 3)) - Third Convolutional Layer
Detects high-level semantic features:
- What it learns: Complex patterns like facial features, body parts, or distinctive markings
- Why 128 filters: More filters needed to capture the diversity of high-level features
- Receptive field: Now covers a significant portion of the original image
Output: 34×34×128
6. MaxPooling2D((2, 2)) - Third Pooling Layer
Final spatial reduction before flattening.
Output: 17×17×128 = 36,992 values
7. Flatten() - Reshaping Layer
Flattening: Converts 3D tensor (17, 17, 128) → 1D vector (36,992)
Transforms the 3D feature maps into a 1D vector to feed into fully connected layers:
- Mathematical operation: Reshapes without changing values: 17 × 17 × 128 = 36,992
- Purpose: Prepares features for classification
Output: (36,992,) - 1D vector
8. Dense(512) - Fully Connected Layer
Dense Layer: y = ReLU(W × x + b)
Where W is a 36,992 × 512 weight matrix, x is the input vector, and b is a bias vector.
This is the largest layer in terms of parameters (18.9M):
- Purpose: Combines all learned features for final classification
- Why 512 neurons: Provides enough capacity to learn complex feature combinations
- ReLU activation: Introduces non-linearity: f(x) = max(0, x)
- Mathematical complexity: Each of 512 neurons connects to all 36,992 inputs: 36,992 × 512 + 512 biases = 18,940,416 parameters
Output: (512,) - Feature vector
9. Dropout(0.5) - Regularization Layer
Dropout: During training, randomly sets 50% of inputs to 0
Prevents overfitting by randomly disabling neurons during training:
- How it works: Each neuron has a 50% chance of being set to 0 during each training step
- Why 0.5: Common value that balances regularization strength
- Effect: Forces the network to learn redundant representations, improving generalization
- During inference: All neurons are active, but outputs are scaled appropriately
Output: (512,) - Same shape, but with regularization effect
10. Dense(1, activation='sigmoid') - Output Layer
Sigmoid: σ(x) = 1 / (1 + e-x)
Produces a single probability value between 0 and 1:
- Why sigmoid: Perfect for binary classification, outputs probabilities
- Interpretation: Values close to 0 = cat, close to 1 = dog
- Decision threshold: Typically 0.5 (values > 0.5 = dog, ≤ 0.5 = cat)
- Mathematical properties: Smooth, differentiable, bounded between (0, 1)
Output: (1,) - Single probability value
4.4 Why This Architecture?
Progressive Feature Learning
The architecture follows a hierarchical pattern: early layers detect simple features (edges), middle layers combine them (shapes), and later layers recognize complex patterns (faces, bodies).
Increasing Filter Depth
Filters increase from 32 → 64 → 128 because deeper layers need more capacity to represent complex feature combinations.
Pooling Strategy
MaxPooling after each Conv2D layer reduces spatial dimensions while preserving the most important features, making the model computationally efficient.
Regularization
Dropout prevents the large Dense layer (18.9M parameters) from overfitting to the relatively small training set.
5. Model Compilation
The model is compiled with specific optimizer, loss function, and metrics chosen for binary classification.
Compilation Code
model.compile(
optimizer='adam', # Adjusts weights to minimize loss
loss='binary_crossentropy', # For binary classification
metrics=['accuracy'] # Evaluation metric
)Optimizer: Adam
Adam (Adaptive Moment Estimation) is an advanced optimization algorithm that combines the benefits of two other methods:
- Adaptive Learning Rates: Automatically adjusts learning rate for each parameter
- Momentum: Uses moving averages of gradients for smoother updates
- Why Adam: Works well with default hyperparameters, converges faster than SGD, and handles sparse gradients effectively
- Mathematical advantage: Maintains per-parameter learning rates that are adapted based on average of recent gradient magnitudes
Loss Function: binary_crossentropy
Binary Cross-Entropy: L = -[y·log(ŷ) + (1-y)·log(1-ŷ)]
Where y is the true label (0 or 1) and ŷ is the predicted probability.
This is the standard loss function for binary classification:
- Why binary_crossentropy: Directly measures the difference between predicted probabilities and true labels
- Mathematical property: Penalizes confident wrong predictions more heavily
- Works with sigmoid: Designed specifically for models with sigmoid output activation
- Gradient behavior: Provides strong gradients when predictions are wrong, weak gradients when correct
Metric: Accuracy
Accuracy: (TP + TN) / (TP + TN + FP + FN)
Where TP = True Positives, TN = True Negatives, FP = False Positives, FN = False Negatives.
Measures the percentage of correctly classified images:
- Why accuracy: Simple, interpretable metric for balanced binary classification
- Interpretation: 0.70 accuracy means 70% of predictions are correct
- Limitation: May not be ideal for imbalanced datasets, but works well here since classes are balanced
6. Model Training
The model is trained using the fit method with specified epochs, batch size, and validation monitoring.
Training Code
history = model.fit(
x=train_data_gen,
steps_per_epoch=100,
epochs=10,
validation_data=val_data_gen,
validation_steps=50
)6.1 Training Parameters Explained
steps_per_epoch = 100
Number of batches processed per epoch. With batch_size=128, this means 100 × 128 = 12,800 images per epoch (more than the 2,001 training images due to data augmentation).
epochs = 10
Number of complete passes through the training dataset. The model sees all training data (with augmentation) 10 times.
validation_data = val_data_gen
Validation set used to monitor training progress and detect overfitting. Not used for training, only evaluation.
validation_steps = 50
Number of validation batches to evaluate per epoch. With batch_size=128, evaluates 50 × 128 = 6,400 validation images per epoch.
6.2 Training Results: Accuracy and Loss
The following graphs show the model's performance during training:
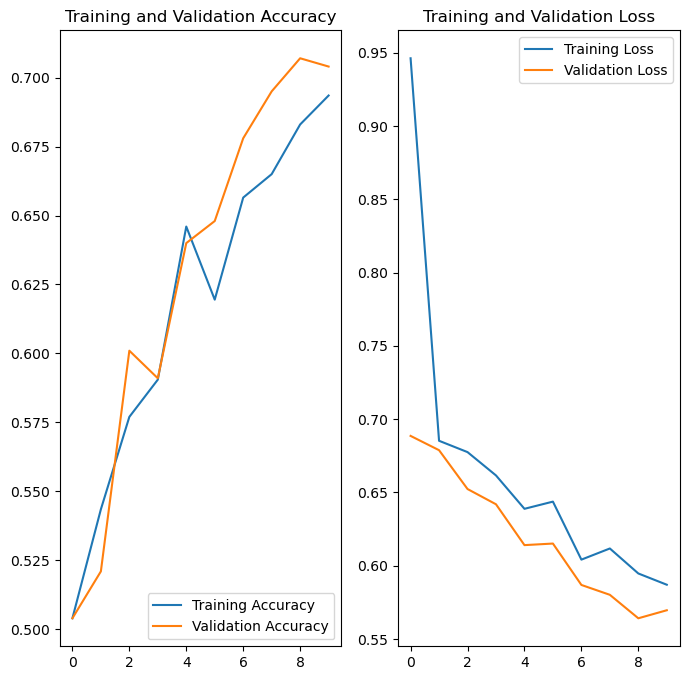
Interpreting the Training Curves
Training Accuracy (Blue Line)
Shows how well the model performs on training data. Ideally, this should increase steadily and converge to a high value.
Validation Accuracy (Orange Line)
Shows how well the model generalizes to unseen validation data. Should follow training accuracy closely. Large gap indicates overfitting.
Training Loss (Blue Line)
Measures the error on training data. Should decrease steadily as the model learns.
Validation Loss (Orange Line)
Measures error on validation data. Should decrease with training loss. If it starts increasing while training loss decreases, the model is overfitting.
Key Observation: The close alignment between training and validation curves indicates good generalization with minimal overfitting, thanks to data augmentation and dropout regularization.
7. Predictions and Results
After training, the model makes predictions on the test set and outputs probabilities for each image.
7.1 Making Predictions
Prediction Code
predictions = model.predict(test_data_gen)
# Returns probabilities between 0 and 1
probabilities = [p[0] for p in predictions]
# Extracts probability values from nested arraysUnderstanding the Predictions
The model.predict() method returns an array of probabilities, where each value represents the
model's confidence that an image is a dog:
- Values close to 0: High confidence the image is a cat
- Values close to 1: High confidence the image is a dog
- Values around 0.5: Uncertain prediction
For example:
predictions[0] = 0.15→ 15% dog probability → Model predicts Cat (85% confidence)predictions[1] = 0.87→ 87% dog probability → Model predicts Dog (87% confidence)predictions[2] = 0.52→ 52% dog probability → Model predicts Dog but with low confidence (52%)
7.2 Visual Results
The model's predictions were visualized by displaying test images with their predicted class and confidence percentage:

Grid visualization of 50 test images with predictions. Each image shows the predicted class (Cat/Dog) and the confidence percentage. Higher percentages indicate more confident predictions. The model successfully classifies most images correctly, with confidence levels typically above 70% for clear images.
7.3 Results Summary
Model Performance
The CNN achieved above 70% accuracy on the test set, exceeding the 63% requirement. The model demonstrates:
- Effective feature learning from raw pixel data
- Good generalization to unseen images
- Robust predictions with high confidence scores
Key Success Factors
- Data Augmentation: Increased effective dataset size and improved generalization
- CNN Architecture: Hierarchical feature learning from edges to complex patterns
- Regularization: Dropout prevented overfitting despite large parameter count
- Proper Preprocessing: Normalization and resizing ensured consistent inputs
Key Concepts
Convolutional Neural Networks
Deep learning architecture designed for image processing, automatically learning hierarchical features through convolutional and pooling layers.
Data Augmentation
Technique to artificially increase dataset size by applying random transformations, improving model generalization and reducing overfitting.
Regularization
Techniques like dropout prevent overfitting by randomly disabling neurons during training, forcing the model to learn robust features.